Cloud Spanner Cloud Instance
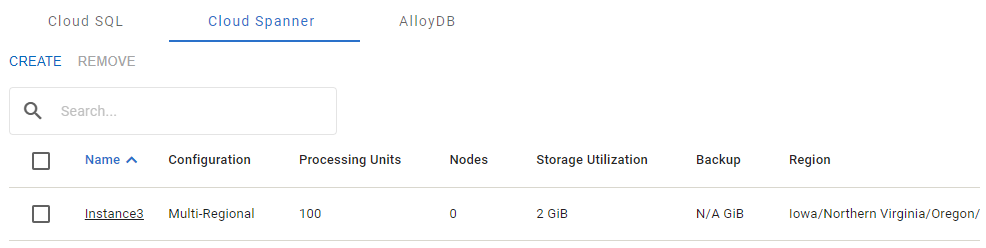
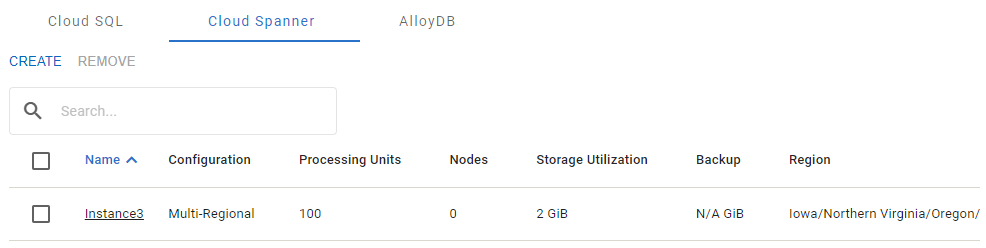
The Cloud Spanner tab
The Cloud Spanner instance has the following properties:
Add Instance
To add a Cloud Spanner cloud instance:
In the Cloud Spanner tab, press the Create button.
In the Choose databases to migrate panel, select the sources to migrate to the cloud instance.
In the Cloud Instance Information panel, specify:
Instance Group
Instance Name
Target Platform: GCP Cloud Spanner.
Configuration: Regional or Multi-Region.
Compute Unit: Processing Units or Nodes.
Region
Committed Usage
Storage Utilization. Calculated automatically based on the cumulative size of the sources selected, with a percentage padding to allow for growth and operation.
Backup
Press the Confirm button to save the configuration, or the Cancel button to discard it.
The Instance Configuration dialog
Compute Unit and Sizing
Cloud Spanner has characteristics and limits that affect the Processing Units or Nodes count settings.
The initial value is automatically calculated and assigned in an attempt to adhere to the following limits:
Maximum database storage allowed per node of 4 TiB.
Maximum number of databases allowed per node of 100.
Maximum read operations per second allowed per node of 10K ops/sec (14K if multi-region).
Maximum write operations per second allowed per node of 2K ops /sec (1.8K if multi-region).
Region-specific maximum node count per project.
To accommodate real-world operational scenarios, additional resources are allocated to the underlying required resources to allow natural growth and spike usage.
mMC collects the data sizes and various object counts during the source scanning.
Workload data is collected from AWR reports in Oracle, and via Extended Scan mode in mMC for other database engine types.
Attempting to under-provision the target instance concerning the sources selected to migrate into it produces an error.
For external documentation related to sizing and limitations, see: